AI-Assisted ADRs in Markdown
Use MADR, Git, and AI review prompts to draft Architecture Decision Records your team can trust.

Architecture Decision Records (ADRs) capture the “why” behind architectural choices in a form your team can review, diff, and link to implementation work. When ADRs live in your repo as Markdown, they become part of the same workflow you already trust: pull requests, code review, and Git history.
This article shows how to standardize on the MADR format, keep ADRs maintainable over time, and use AI to draft and critique ADRs without giving up human accountability for evidence, alternatives, and trade-offs.
Why ADRs belong in your repo
An Architecture Decision Record (ADR) is a short, durable note about one architectural decision. It captures the context, the choice, and the consequences so future readers can answer “why did we do it this way?” without archaeology.
ADRs work best when they live where engineering work already happens: in the repo, in Markdown, reviewed like code. Martin Fowler’s guidance is pragmatic: keep ADRs short, store them with the code, number them in a monotonic sequence, and treat them as a log. That “log” framing matters. Once a decision is accepted, you don’t rewrite it to match today’s thinking. If the decision changes, you create a new ADR that supersedes the old one and link them.
AI lowers the friction. It can draft from notes, extract decision drivers, propose comparable options, and check whether the ADR has the expected sections. It also adds risk: hallucinated context, overconfident claims, and options that were never discussed. Treat AI as a draft and critique tool, not as the decision owner.
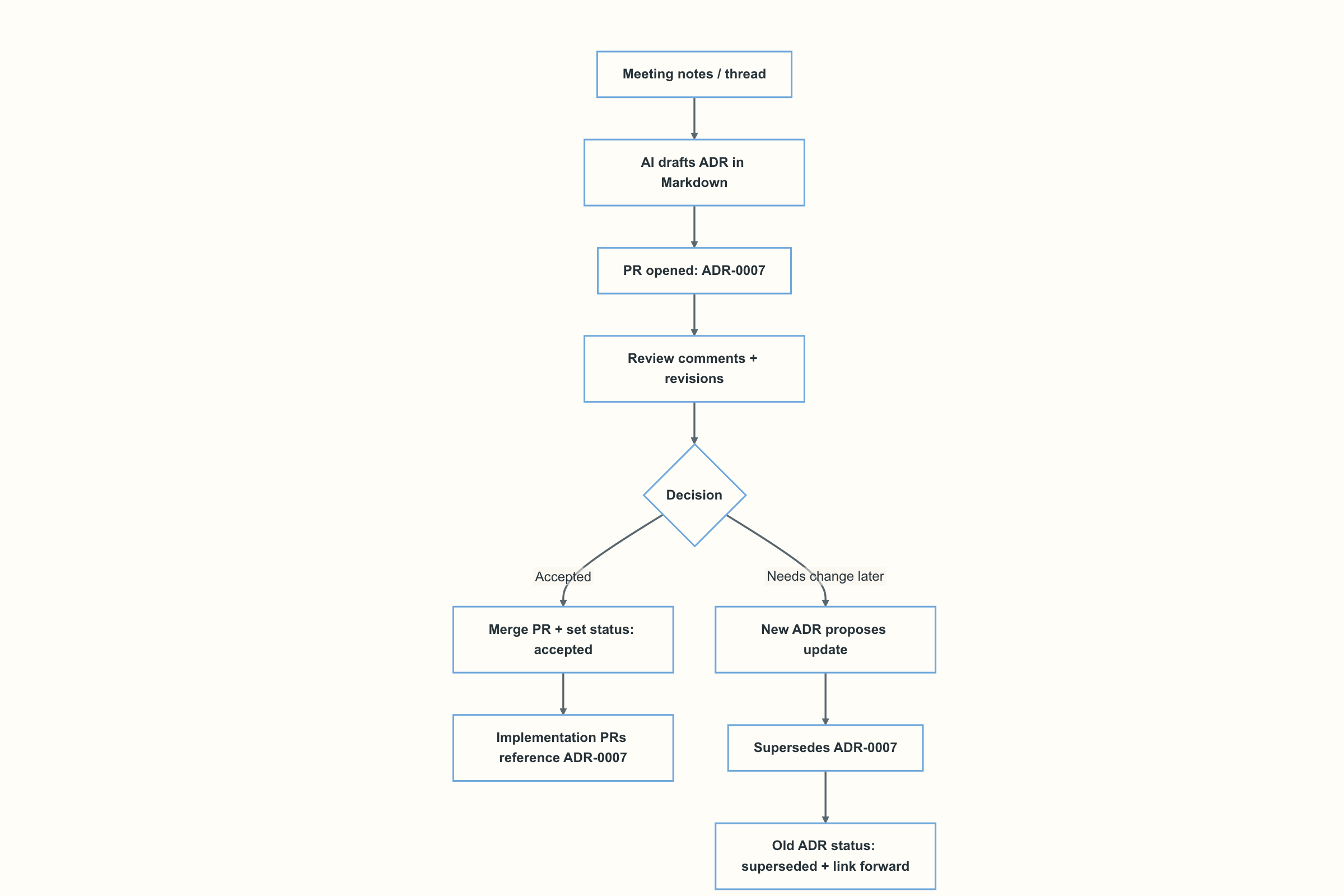
Choose MADR for Markdown ADRs
What MADR is and why teams adopt it
MADR (Markdown Architectural Decision Records) is a standardized ADR format designed for Markdown and repo workflows. It gives teams consistent headings, shared expectations, and fewer “where do we put this?” debates during review.
The canonical adr/madr repo ships full and minimal templates, each with explanation-heavy and bare variants. Start with the bare minimal template for day-to-day decisions, then add optional sections only when the team needs them. Pin the template version you use so ADRs do not silently drift across years and repos.
| Template variant | Best for | Trade-off |
|---|---|---|
| Full | Decisions with many stakeholders / complex trade-offs | More headings to maintain |
| Minimal | Most teams’ day-to-day decisions | Less room for extra context unless you add it |
| “With explanations” | Onboarding and first few ADRs | More text noise in diffs |
| “Bare” | Mature teams with muscle memory | Less guidance; reviewers must enforce quality |
The MADR sections AI should draft (and humans must validate)
Olaf Zimmermann’s MADR primer frames the core as context/problem, decision, and consequences. Supplemental sections like decision drivers, considered options, metadata, validation, and links make reviews sharper. AI is useful for extraction and organization. Humans still need to verify that it did not invent constraints or launder weak options.
| MADR section | What AI is good at | What humans must validate |
|---|---|---|
| Context and Problem Statement | Summarizing notes into a crisp problem statement | Scope boundaries, correctness, missing constraints |
| Decision Drivers | Extracting drivers and clustering duplicates | Priority/order, “driver vs solution” confusion |
| Considered Options | Generating a comparable option set | Whether options were actually on the table; abstraction-level consistency |
| Decision Outcome | Drafting a justification tied to drivers | The real rationale; evidence vs opinion; stakeholder alignment |
| Consequences | Enumerating impacts across ops/security/cost/DX/migration | Second-order effects, mitigations, and what you’ll actually do |
Status and lifecycle fields that make ADRs maintainable
MADR metadata such as status, date, deciders, consulted, and informed turns ADRs into an auditable log. It also aligns with Fowler’s rule: once accepted, don’t rewrite history. Supersede with a new ADR and link forward.
proposed → accepted → superseded (by ADR-00NN)
Use a repo-native ADR workflow
Folder conventions and discoverability in docs-as-code repos
Pick one home for ADRs and keep it boringly consistent. MADR’s quick start suggests docs/decisions; docs/adr and doc/adr are also common. The exact path matters less than stability, because stable paths make links, scripts, and onboarding docs reliable.
repo/
docs/
decisions/
0001-use-postgresql.md
0002-adopt-event-driven-integration.md
README.md
Numbering and naming conventions (and how to avoid PR collisions)
Use a monotonic sequence number plus a short slug: nnnn-short-slug.md. It sorts cleanly, stays stable as titles evolve, and gives you a compact handle for cross-references such as ADR-0007.
Parallel work is where this breaks down. Two PRs can both add 0007-.... This is a real pain point discussed in the MADR repo. Three mitigations that keep process light are:
- Reserve numbers during ADR kickoff (often a quick comment in a tracking issue).
- Generate “next available” via a tiny script.
- Use a temporary
xxxx-prefix and renumber on merge (only if your team accepts link churn).
| Collision mitigation | How it works | Pros | Cons |
|---|---|---|---|
| Reserve numbers | Assign an ADR number in an issue/comment before drafting | Simple; no tooling | Requires coordination |
| “Next available” script | Script scans folder and prints next NNNN | Fast; reduces human error | Still possible to race in parallel |
Temporary xxxx- then rename | Draft without final number; rename at merge | Avoids collisions early | Link churn; more review noise |
The ADR index: making decisions searchable and reviewable
An index turns a folder of files into a decision log you can scan and de-duplicate against. Keep it as a table of contents. Include number, title, status, date, and links (issue/PR plus superseding relationships). Avoid copying the ADR narrative into the index.
| ADR | Title | Status | Date | Links |
|---:|---|---|---|---|
| 0001 | Use PostgreSQL | accepted | 2026-05-14 | Issue #231, PR #245 |
| 0002 | Adopt event-driven integration | proposed | 2026-06-02 | PR #268 |
| 0003 | Replace queue with Kafka | superseded | 2026-06-20 | Superseded by [0009](0009-managed-kafka.md) |
Copy a lightweight MADR template
Provide a practical MADR template teams can standardize on
Use one pinned template that every ADR can be reviewed against. The “bare minimal” MADR template is a good default because it stays lightweight while preserving comparability across decisions.
---
status:
date:
deciders:
consulted:
informed:
---
#
## Context and Problem Statement
## Decision Drivers
*
## Considered Options
*
## Decision Outcome
Chosen option: "", because
### Consequences
* Good, because
* Bad, because
Treat the headings as a contract. Add optional sections consistently, not ad hoc per ADR. A one-line note such as “Template: MADR 4.0.0 (adr/madr)” helps future edits stay anchored.
Prompting AI to draft MADR sections from meeting notes (without losing nuance)
AI drafting works best when you provide raw inputs and constrain the model to stay evidence-based. Prompts that demand traceability and uncertainty markers are easier to audit in review.
You are drafting a MADR ADR. Use ONLY the notes below as evidence.
1) Extract 5–8 decision drivers as bullets. After each driver, cite the note line(s).
2) List 3–5 considered options at the same abstraction level. For each: pros/cons/risks.
3) Draft consequences across ops, security, cost, DX, and migration.
If information is missing, add an "Assumptions" bullet with "UNCONFIRMED:".
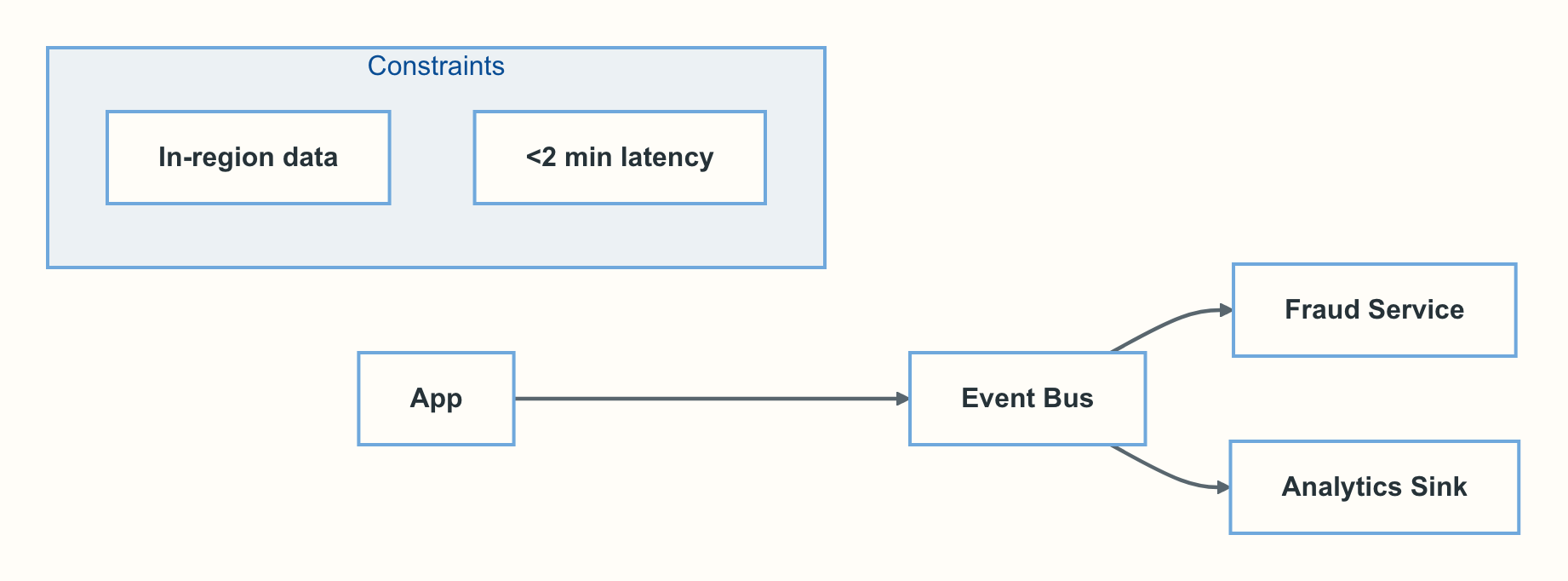
Mini-example input:
[1] Current cron ETL misses late events; on-call pages weekly.
[2] Need near-real-time (<2 min) for fraud alerts.
[3] Team knows Postgres; limited Kafka experience.
[4] Budget prefers managed services.
[5] Compliance: data must stay in-region.
[6] Peak 5k events/sec; expect 3x in 12 months.
Expected draft shape: decision drivers cite [1]–[6], and options stay comparable, such as “Managed Kafka”, “Managed Kinesis/PubSub”, and “Postgres LISTEN/NOTIFY + workers”.
 Illustrative guardrails card: require traceability and comparable options; avoid invented constraints, mixed abstraction levels, one-sided outcomes, and rewritten history. Interactive spec.
Illustrative guardrails card: require traceability and comparable options; avoid invented constraints, mixed abstraction levels, one-sided outcomes, and rewritten history. Interactive spec.
Using mdedit.ai effectively in an offline-first docs-as-code workflow
In mdedit.ai, generate the MADR skeleton inside docs/decisions/. Then use contextual AI chat against the open ADR plus nearby docs (runbooks, RFCs, constraints) to catch contradictions before PR review.
When a diagram clarifies context, keep it small and reviewable using Mermaid.
Review AI drafts like decisions, not prose
A human-first review checklist for MADR completeness
Once AI produces a structured draft, the job shifts from writing to validation. Treat the draft as a hypothesis until it captures the real constraints, alternatives, and trade-offs.
- Context and Problem Statement: bounded, specific, and explicit about what’s out of scope.
- Decision Drivers: stated as drivers (not solutions), and implicitly prioritized.
- Considered Options: comparable at the same abstraction level.
- Decision Outcome: explains “why this, not that,” referencing drivers.
- Consequences: includes negative and second-order effects (operational load, migration risk, security/compliance, cost).
Bad vs better (context):
- Bad: “We need a better messaging system.”
- Better: “We need sub-2-minute event delivery for fraud alerts, in-region only, at 5k events/sec peak, without adding 24/7 ops burden.”
Bad vs better (consequences):
- Bad: “This will improve reliability.”
- Better: “Improves replay and backpressure handling, but adds on-call surface area (consumer lag, partition hot-spotting) and requires a migration window for dual-write.”
PR review checklist (copy/paste):
- Problem statement is specific; in-scope/out-of-scope is explicit
- Drivers are drivers (not solutions) and reflect real constraints
- ≥2 alternatives listed; options are comparable at the same abstraction level
- Outcome explains “why this, not that” (ties back to drivers)
- Consequences include at least one negative / second-order effect + mitigation idea
- Status/date/deciders filled in; links to issue/PR included
AI-assisted review prompts that reduce bias and improve trade-off clarity
AI is most valuable in review when it generates pressure, not praise. Use it as a critic that produces questions, counterarguments, and explicit uncertainty. That helps humans resolve the hard parts in PR discussion.
Act as a skeptical reviewer. Argue against the chosen option.
1) Identify at least 2 viable missing options at the same abstraction level.
2) List failure modes + operational risks; propose mitigations.
3) What constraints could invalidate this decision in 6–12 months?
Return: questions to ask + assumptions to validate (mark UNCONFIRMED).
Good output should name missing options, operational risks, and assumptions to validate. For example: “Missing option: managed Pub/Sub equivalent”; “Missing risk: cross-region failover behavior”; “Assumption to validate: vendor SLA meets compliance audit needs.”
Review mechanics in Git: PR-based readout and comment resolution
Run ADR reviews like code reviews. Keep the unit of work small: one decision per ADR, one ADR per PR. A “readout” style review works well. Start with written comments, then hold a time-boxed discussion with a lean attendee list. This approach also matches guidance from large-scale ADR usage writeups, such as the AWS Architecture Blog.
Keep ADRs short by linking to longer design docs instead of embedding them.
PR description template:
ADR: 0012 - <title>
Decision deadline: YYYY-MM-DD
Summary: <1–2 sentences>
Stakeholders: Deciders: @... | Consulted: @... | Informed: @...
Links: Issue #... | Design doc: <url> | Related ADRs: 0007, 0009
Review focus: drivers, options comparability, consequences completeness
Keep ADRs alive with links and light checks
Linking ADRs to issues, PRs, and commits (traceability patterns)
Once an ADR is merged, its value compounds when readers can move from “why” to “where it changed.” Put links where reviewers expect them, and mirror the ADR number in Git metadata so search works across tools.
In the ADR, keep a small link hub (often a “More Information” section in MADR) that points to discussion and implementation:
## More Information
- Related: #231 (problem statement), https://github.com/acme/repo/pull/245 (ADR review PR)
- Implemented by: https://github.com/acme/repo/pull/260, https://github.com/acme/repo/pull/277
- Supersedes: [0007](0007-cache-auth-tokens.md)
- Superseded by: [0012](0012-rotate-tokens-with-oidc.md)
In Git, repeat the handle in human-scannable places:
PR title: ADR-0012: Rotate tokens with OIDC
Merge commit: Merge PR #277: implement OIDC rotation (ADR-0012)
If you want stronger “link/supersede” semantics, tools like git-adr (which stores ADRs in git notes rather than Markdown files) are a useful inspiration. File-based Markdown ADRs still keep reviews and diffs straightforward for most teams.
| Link location | Pattern | Why it helps |
|---|---|---|
| ADR body (“More Information”) | Related issue/PR + implementation PRs | Readers can jump from rationale to change |
| PR title | ADR-00NN: <title> | Makes search and release notes easy |
| Merge commit message | ... (ADR-00NN) | Preserves traceability even outside GitHub/GitLab UI |
| Index entry | Status + supersedes/superseded-by | Keeps the decision log navigable |
Superseding an ADR without losing history
Supersede when reality changes: new constraints, scale, compliance, or failed assumptions. Do not rewrite accepted ADRs. Create a new one and link both records so the log stays honest.
---
status: superseded
---
Superseded by: [0012](0012-rotate-tokens-with-oidc.md)
In the new ADR, add a clear back-link (“Supersedes: 0007”). Explain what changed and why. Avoid rewriting the old rationale.
Lightweight automation: consistency checks that don’t annoy teams
Automation should protect conventions without trying to grade writing. Keep CI fast and actionable: enforce filenames, required headings, allowed statuses, and index updates when a new ADR is added.
import re
import sys
import pathlib
ADR_DIR = pathlib.Path("docs/decisions")
NAME_RE = re.compile(r"^\d{4}-[a-z0-9-]+\.md$")
REQUIRED = [
"## Context and Problem Statement",
"## Decision Outcome",
"### Consequences",
]
ALLOWED_STATUS = {"proposed", "accepted", "superseded"}
for p in ADR_DIR.glob("*.md"):
if p.name == "README.md":
continue
if not NAME_RE.match(p.name):
sys.exit(f"Bad ADR filename: {p}")
txt = p.read_text(encoding="utf-8")
for h in REQUIRED:
if h not in txt:
sys.exit(f"Missing heading {h} in {p}")
# Very lightweight front matter check: only validate if a status key exists.
m = re.search(r"(?m)^\s*status:\s*([a-z-]+)\s*$", txt)
if m and m.group(1) not in ALLOWED_STATUS:
sys.exit(f"Bad status '{m.group(1)}' in {p}")
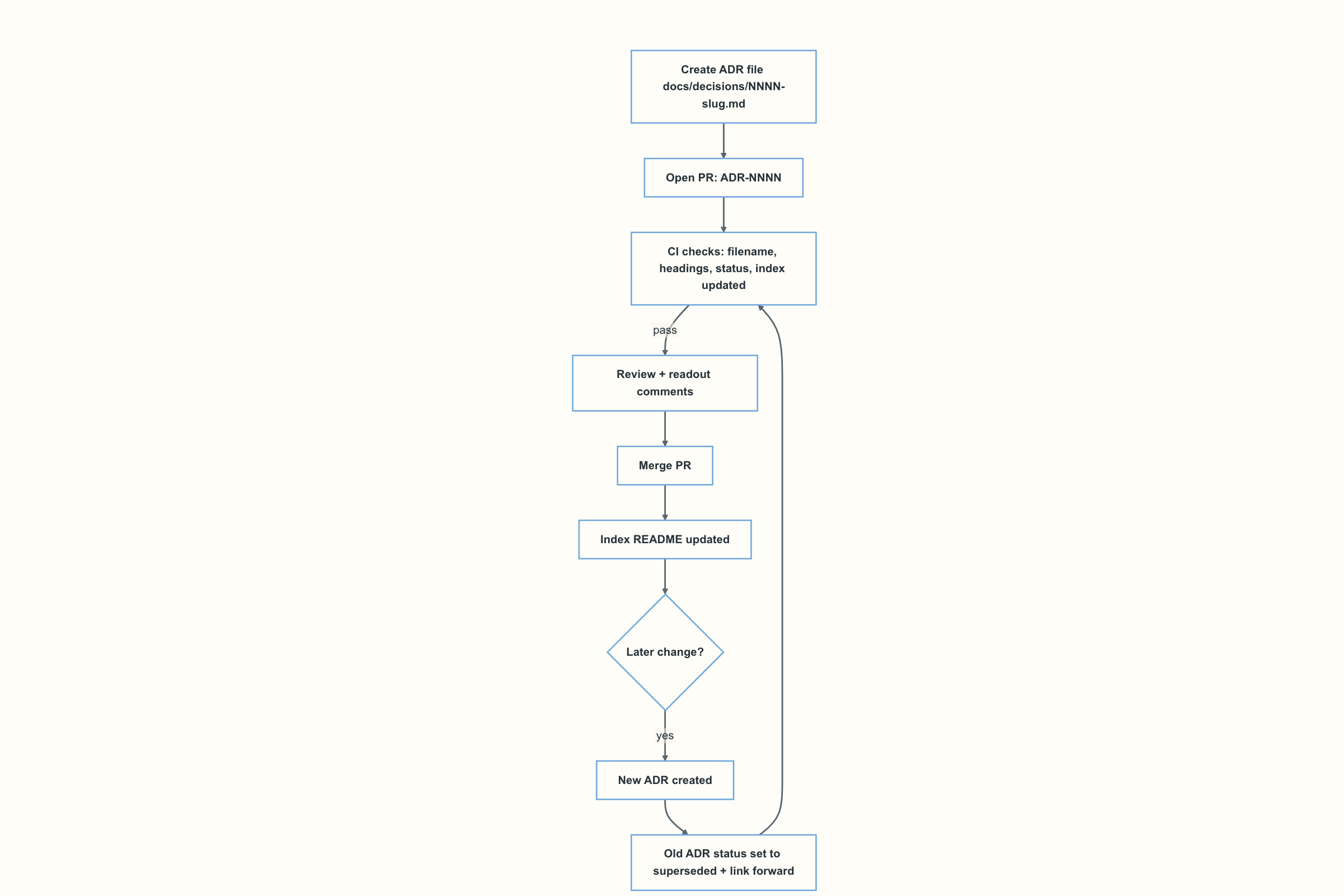
Start small
Adopt MADR with AI the same way you adopt any engineering practice: start small, make it repeatable, then add guardrails once the team feels the value.
Start with 3–5 decisions that will otherwise get re-litigated: database choice, API style, deployment model, auth approach, or eventing. Pick decisions that already have an issue, a deadline, and stakeholders. Avoid hypothetical debates.
Roll out in a lightweight sequence: standardize the folder, filename convention, pinned template, and index; use AI drafting prompts to reduce the blank-page tax; keep humans responsible for correctness and trade-offs; then add CI checks once the practice is working.
Define a clear “definition of done” for an accepted ADR so reviews don’t stall:
- File is in
docs/decisions/and namedNNNN-slug.md. - Status is
accepted, date is set, and deciders are listed. - Context is bounded; at least 2 alternatives are recorded.
- Consequences include at least one negative/second-order effect.
- Linked to the driving issue and the ADR PR; implementation PRs reference
ADR-NNNN. - Index (
docs/decisions/README.md) updated in the same PR.
If you do only three things, do these: standardize on MADR, use AI to draft and challenge the record (not to decide), and use Git links plus superseding to keep the decision log honest as the system evolves.